 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariDAX already offered two ranking functions so far: RANK.EQ and RANKX. While RANK.EQ is very seldom used, RANKX has been the primary ranking function for a long time. We wrote several articles about RANKX: one of them deals with ranking on multiple columns, a scenario that requires some DAX acrobatics to be solved as described in RANKX on multiple columns with DAX and Power BI.
The new RANK function makes ranking on multiple columns much easier because it offers sorting by multiple columns as a native feature, because it belongs to the family of window functions. Thanks to the concept of current row in window functions, RANK also helps in a subtle issue with RANKX – which despite being rare, might affect ranking on decimal numbers as described in Use of RANKX with decimal numbers in DAX.
We will not show the full syntax options of RANK, because they follow the pattern of window functions introduced here: Introducing window functions in DAX.
As an example, we use a measure that rounds the sales amount to the nearest multiple of 400K, to introduce ties in the ranking:
Rounded Sales = MROUND( [Sales Amount], 400000 )
Let us start with a very brief recap of RANKX. Using RANKX requires complex syntax and attention to detail. The following formula, though correct, comes with a couple of drawbacks that are not intuitive to solve for newbies. Indeed, if we want to obtain a ranking based on the Product[Brand] column using RANKX, we can author the following code:
RANKX =
RANKX (
ALLSELECTED ( 'Product'[Brand] ),
[Rounded Sales], , DESC, DENSE
)
When used in a matrix, at the total level the value displayed does not make much sense.
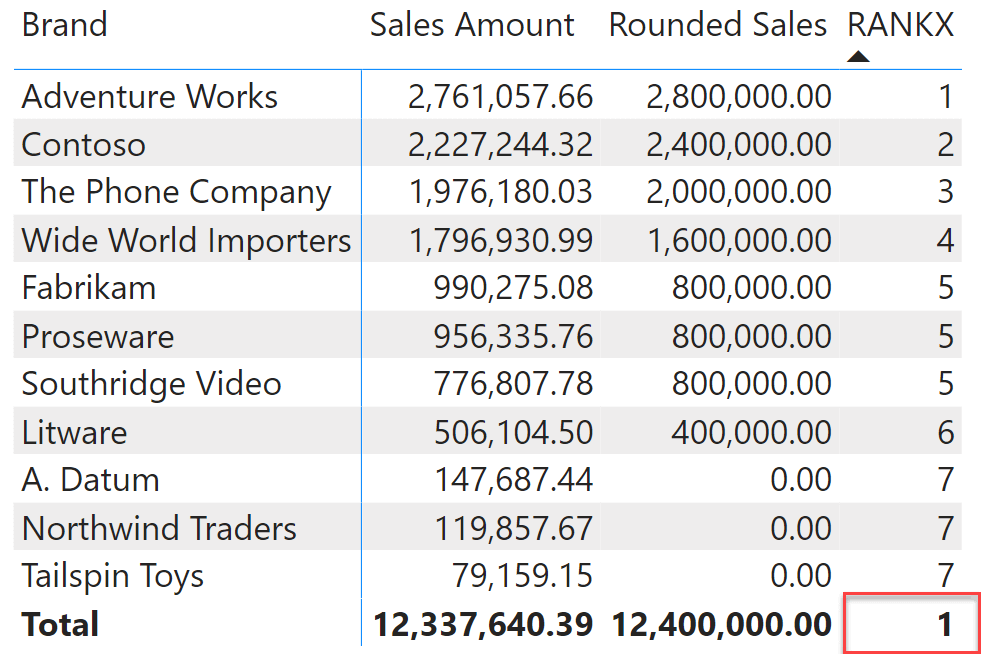
Not only is the value shown at the total level. But any subtotal, if present, would show the same result.
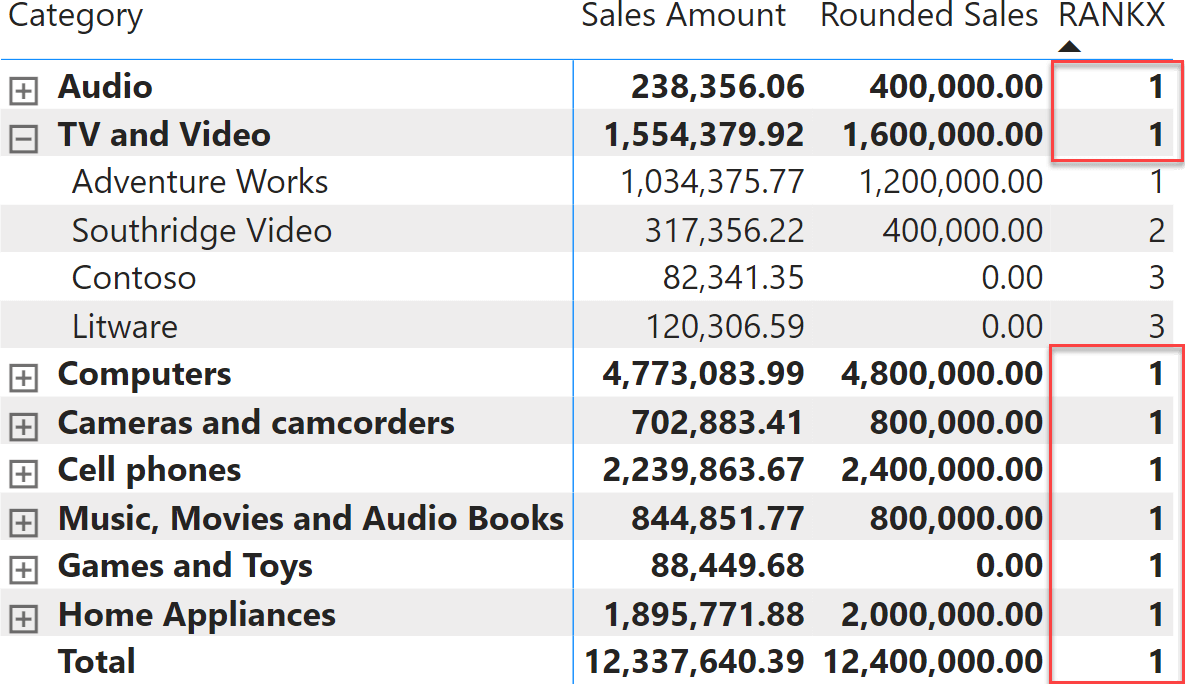
We can solve the problem by using HASONEVALUE or ISINSCOPE. However, the thing is, you need to pay attention to these small details because of the somewhat counterintuitive behavior of RANKX. Moreover, ties are ranked equally using RANKX, like Contoso and Litware in the previous screenshot. Sometimes, this is the desired result. However, we often prefer a ranking that distinguishes between ties, using for example the alphabetic order of the brand as the second order for the ranking. We want a result like the following.
Obtaining this result is an interesting DAX exercise but it is too complex and time consuming. RANK solves the problem in a straightforward manner. Indeed, with RANK you can provide multiple order-by columns with the syntax of window functions. The code of the RANK measure is the following:
RANK =
RANK (
DENSE,
ALLSELECTED ( 'Product'[Brand] ),
ORDERBY ( [Rounded Sales], DESC, 'Product'[Brand], ASC )
)
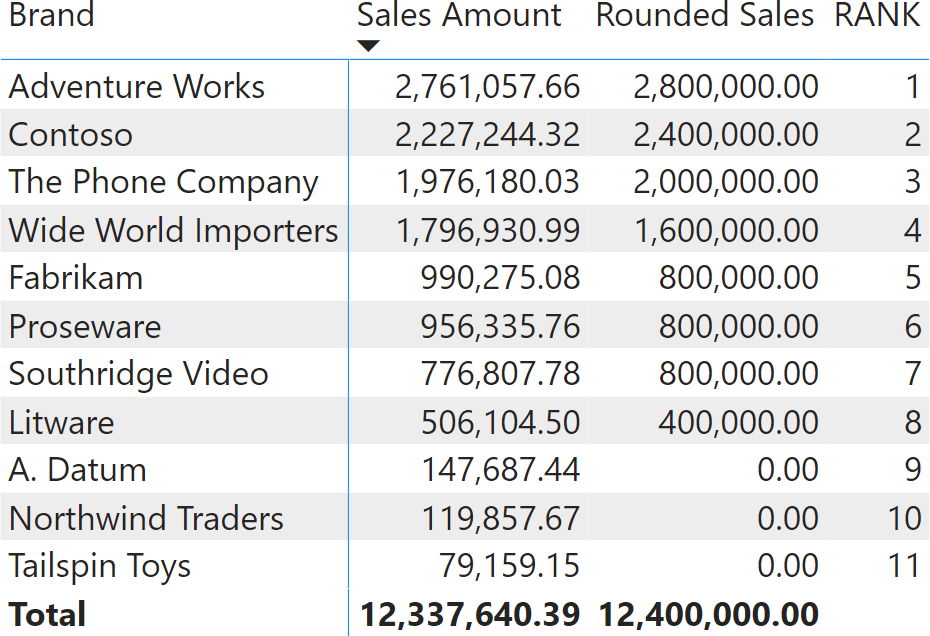
Because RANK ranks the current row against the source table provided, when there is no current row – like at the total level – RANK shows a blank rather than an inaccurate ranking.
As we suggest in the SQLBI+ whitepaper on window functions, we consider it a best practice to precompute the source table of window functions. This adds readability and sometimes may also produce a better query plan. A better formulation of the previous query is the following:
RANK =
VAR SourceTable =
ADDCOLUMNS ( ALLSELECTED ( Product[Brand] ), "@Amt", [Rounded Sales] )
VAR Result =
RANK (
DENSE,
SourceTable,
ORDERBY ( [@Amt], DESC, Product[Brand], ASC )
)
RETURN
Result
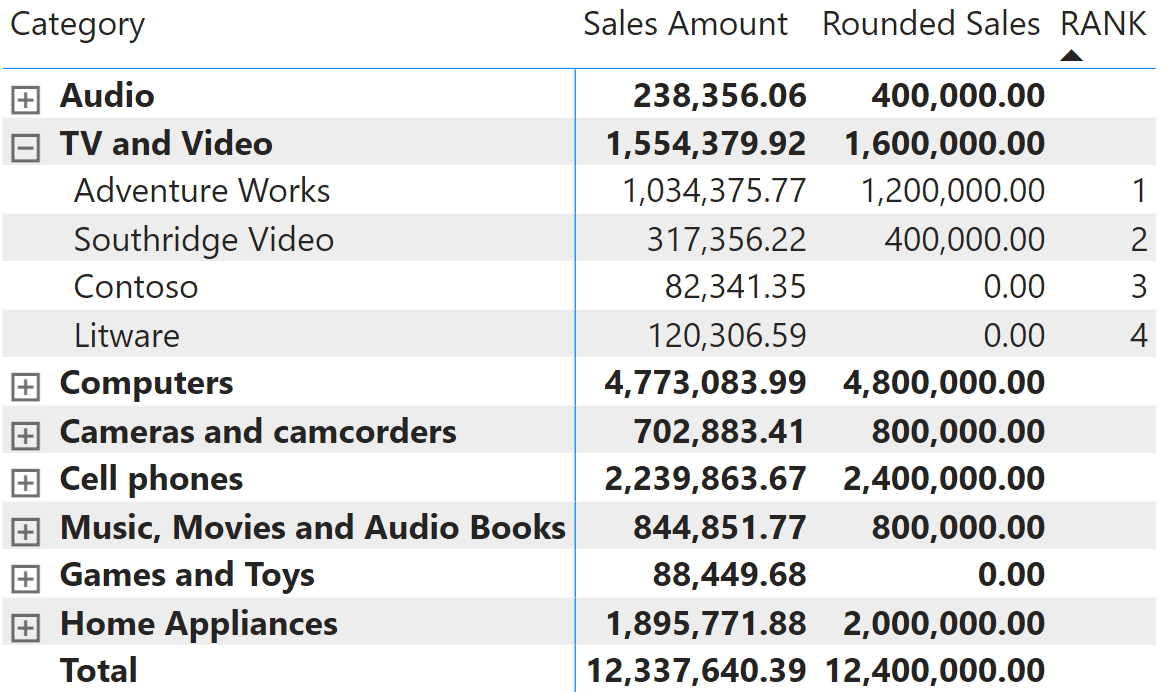
The main reason to make the code more readable is to clearly understand the content of the source table and how the ranked column is computed. By looking at the content of SourceTable, it is clear that the @Amt column is computed in the current filter context where the only column being overridden is Product[Brand]. As such, we know the ranking is local to the current filter context. Indeed, by expanding the matrix to show multiple categories, you can see that the ranking always restarts for each category.
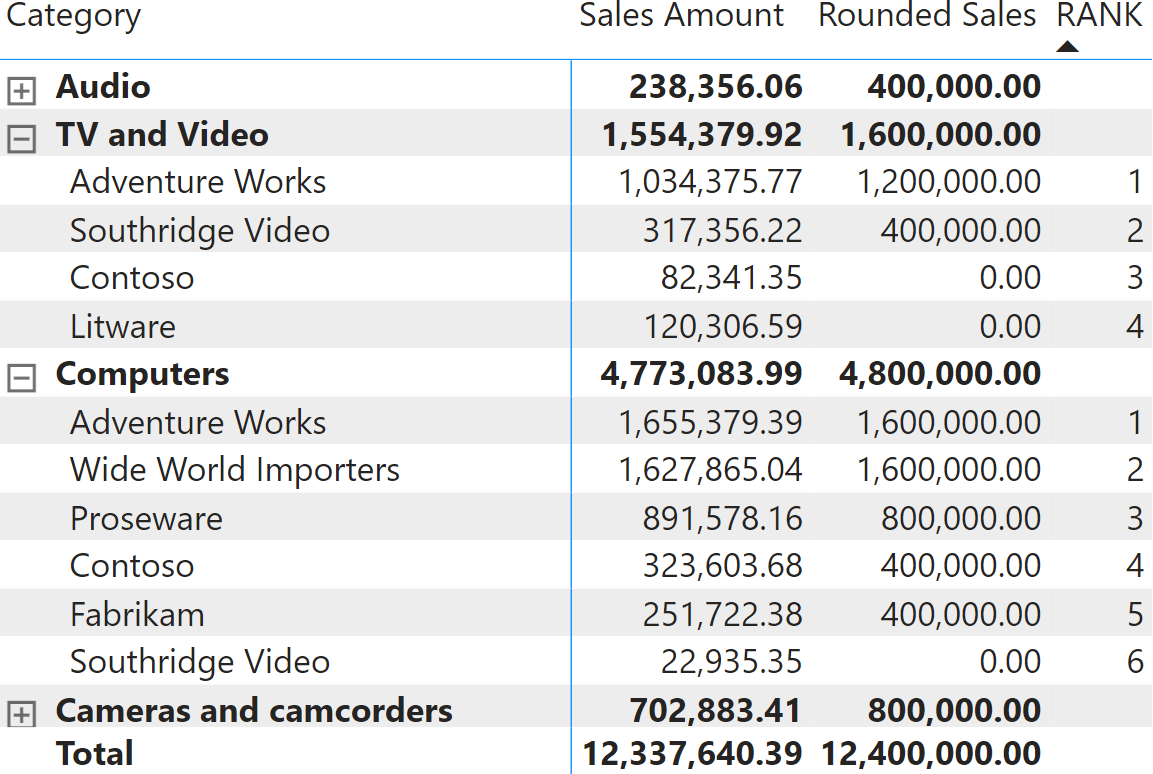
Picturing which portions of the filter context are replaced while evaluating the amount used for the ranking is extremely important to avoid common pitfalls. For example, if we were to rank months against one another, a wrong option would be the following:
RANK Month (Wrong) =
VAR SourceTable =
ADDCOLUMNS (
ALLSELECTED ( 'Date'[Month] ),
"@Amt", [Sales Amount]
)
VAR Result =
RANK (
DENSE,
SourceTable,
ORDERBY ( [@Amt] )
)
RETURN
Result
When used in a matrix, the result is incorrect.
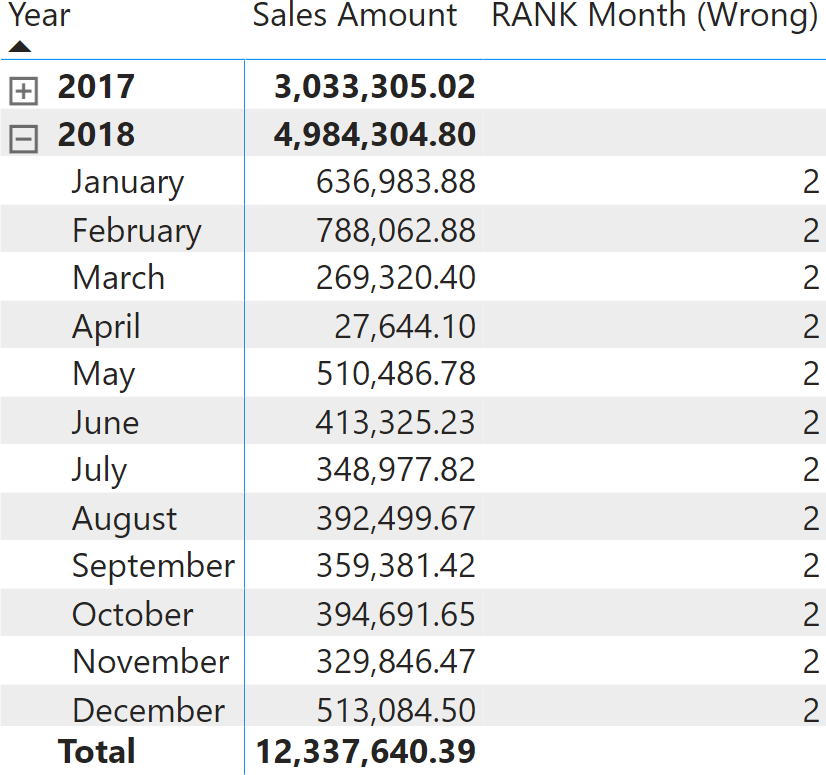
The reason is that the columns in the source table do not replace the correct portion of the filter context. Month is sorted by Month Number, so Month Number is used as part of the query, and results in being filtered. The source table overrides Month (the month name) but not Month Number. A correct formulation is the following:
RANK Month =
VAR SourceTable =
ADDCOLUMNS (
ALLSELECTED (
'Date'[Month],
'Date'[Month Number]
),
"@Amt", [Sales Amount]
)
VAR Result =
RANK (
DENSE,
SourceTable,
ORDERBY ( [@Amt] )
)
RETURN
Result
Overriding the filter context on both Month and Month Number produces the correct result.
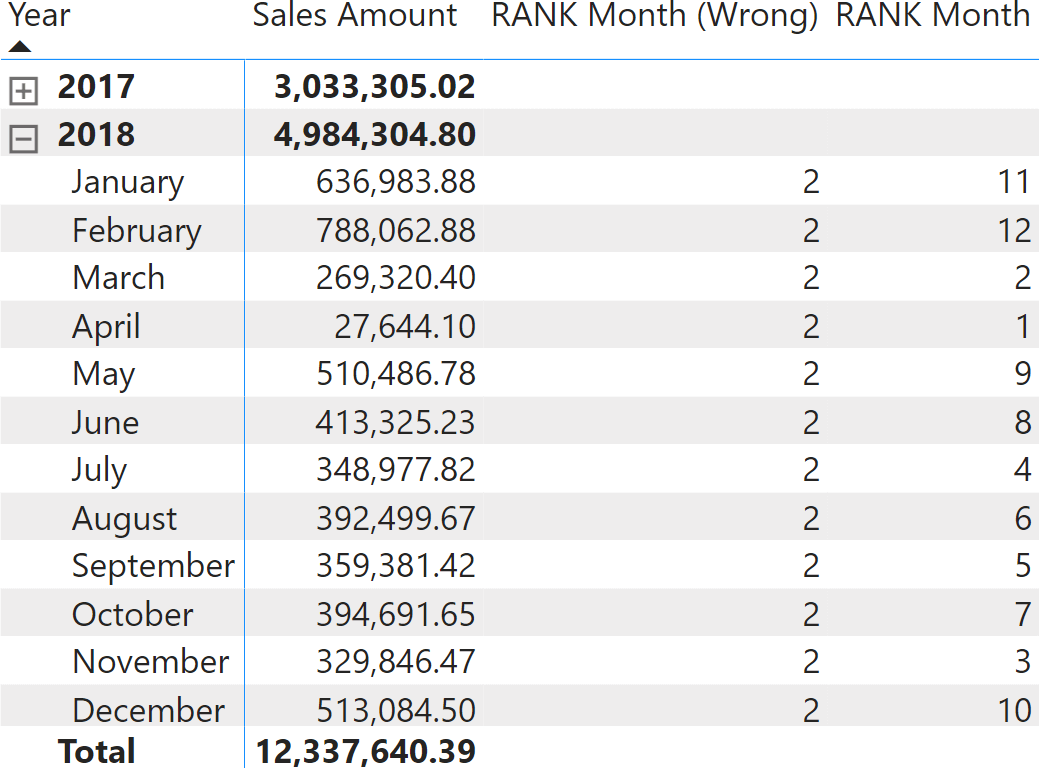
RANK is not a replacement for RANKX. There are a few scenarios where developers can use the third argument of RANKX to rank a value against a configuration table, as explained in Introducing RANKX in DAX. However, these scenarios are rare, and RANK is usually a better option.
Conclusions
RANK is a function that makes ranking of one or multiple columns simple. It shows a more consistent behavior when the ranking should not be displayed directly in the report, and it reduces the number of possible errors in your DAX code. Despite not being a complete replacement for RANKX, it fits perfectly in most scenarios, making it the best ranking function available in DAX today.
Returns the rank of a number in a column of numbers. If more than one value has the same rank, the top rank of that set of values is returned.
RANK.EQ ( <Value>, <ColumnName> [, <Order>] )
Returns the rank of an expression evaluated in the current context in the list of values for the expression evaluated for each row in the specified table.
RANKX ( <Table>, <Expression> [, <Value>] [, <Order>] [, <Ties>] )
Returns the rank for the current context within the specified partition sorted by the specified order or on the axis specified.
RANK ( [<Ties>] [, <Relation>] [, <OrderBy>] [, <Blanks>] [, <PartitionBy>] [, <MatchBy>] [, <Reset>] )
Returns true when there’s only one value in the specified column.
HASONEVALUE ( <ColumnName> )
Returns true when the specified column is the level in a hierarchy of levels.
ISINSCOPE ( <ColumnName> )