 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariWhen you import a table in Power BI, all the strings contained in a text column are stored in a dictionary, which improves the compression and provides excellent query performance when there is a filter with an exact match for the column value. However, reports that apply complex filters on a text column may have performance issues when the dictionary has a large number of values: depending on many other variables, a column with a few thousand unique values might already present a bottleneck, and this is definitely an issue when there are hundreds of thousands of unique strings in a column.
In October 2022, there was an internal optimization in Power BI that has improved the performance of these searches by creating an internal index. Chris Webb described this optimization in his article, Text search performance in Power BI. In this article, we explore how to evaluate whether the optimization is applied and how to measure any performance improvements. As usual, everything comes at a price: creating the index has a cost, that you will see applied to the first query hitting the column. We will also see how to detect this event and the existing limitations for this optimization.
Scenarios for text search in Power BI
With a regular slicer, the user typically selects one or more values, which means that the filter searches for exact matches of the selected items: the entire column value must be identical to one of the selected items. If the user wants to search for any column value that contains a particular substring or matches a specific search pattern, then one option is to use the contains advanced filter in the filter pane.
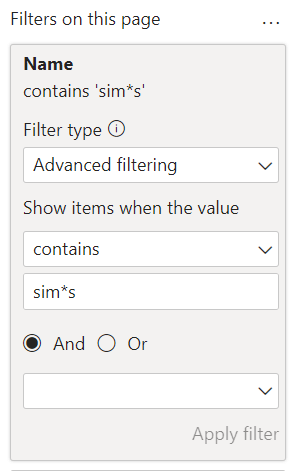
The rule “sim*s” matches customer names such as Sims, Simmons, Simpson, but Simen Aase is also returned by the search. This very search pattern is also available in a report using OKVIZ’s Smart Filter Pro custom visual in filter mode.

Whenever you use one of these user interface filters in a Power BI report, the underlying query contains either SEARCH or CONTAINSSTRING to implement the filter condition in DAX. These functions are not case-sensitive, but they are accent-sensitive. Therefore, Šime Šaric is not included in the results of the filter. We mention the accent-sensitive nature of these functions because it is an essential element to consider for optimization.
Detecting the bottleneck
We consider the following report, where we applied the “sim*s” search pattern by using either the filter pane or Smart Filter Pro.
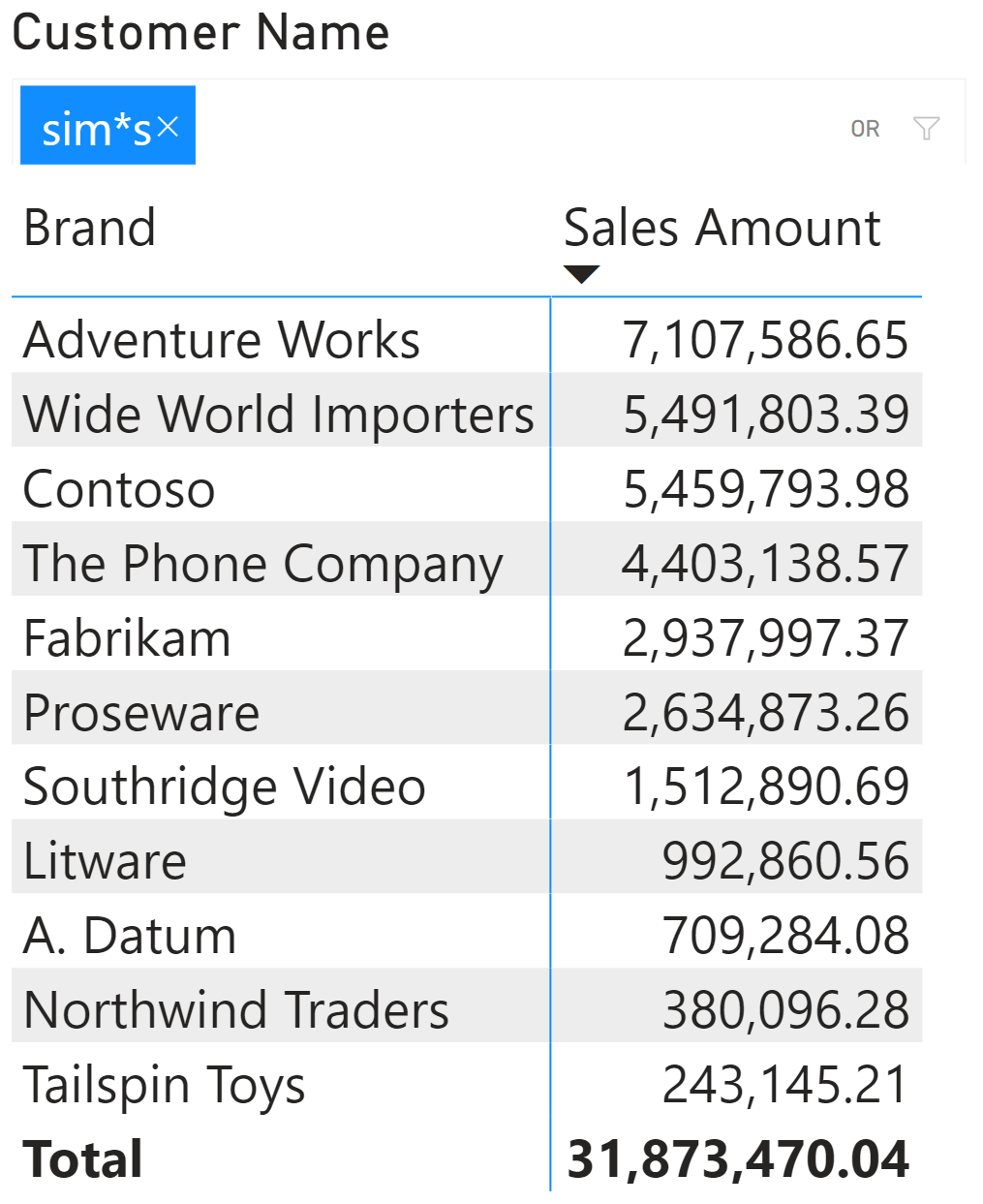
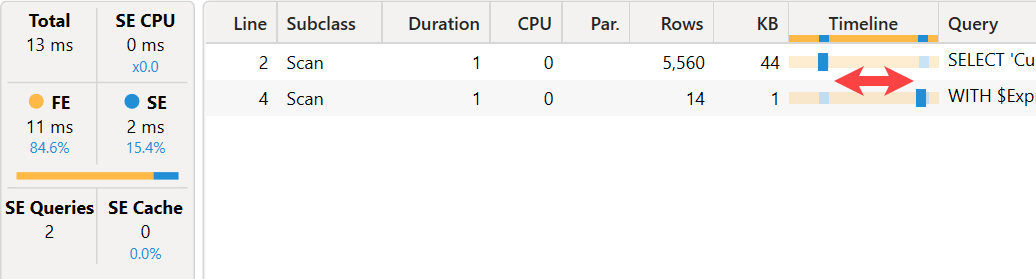
The test is made on a Contoso version with 10 million orders and more than 1.4 million customers. Performance Analyzer reveals that this simple report requires almost 2 seconds to execute the DAX query.
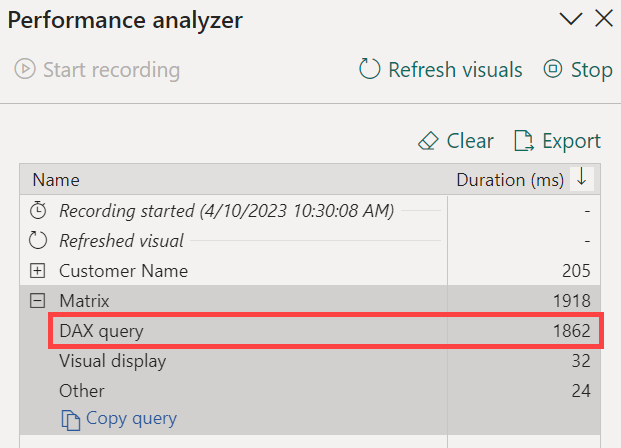
The reason for the bottleneck is the CallbackDataID used to create the filter over Customer[Name] in the batch operation executed by the VertiPaq engine.
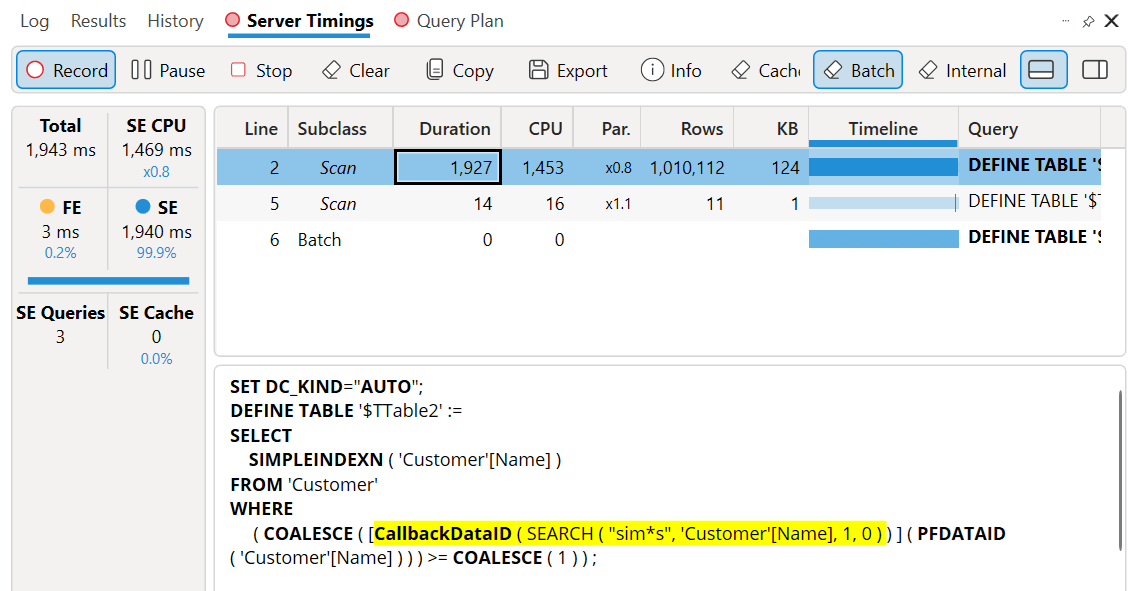
The formula engine executes the SEARCH function for each unique value in Name. While the bitmap index generated for this operation makes the second Scan in the batch extremely fast (just 16 milliseconds of CPU time), the execution of SEARCH in the formula engine for more than one million unique names is causing a performance bottleneck. Moreover, the CallbackDataID does not store the result in the storage engine cache, requiring the same expensive operation for each execution of a DAX query containing the same filter. If the user applies the filter pane to a page with many visuals, the filter cost must be multiplied by the number of visuals displayed.
Because the downloadable version of the sample file is smaller and has only 10,000 orders by just over 5,000 customers, with that sample file, the execution plan of the same report seems more efficient because it does not use a CallbackDataID.
There are two storage engine queries separated by an interval where the formula engine performs its computation. The first xmSQL query retrieves the list of all the customer names:

The second xmSQL query applies the list of customer names that satisfy the filter condition: this list is evaluated by the formula engine between the two storage engine queries:

Although the storage engine queries are cached, the formula engine cost to evaluate the filter is always present with this alternative approach of the query plan. The engine can choose one of these two approaches depending on the number of unique names in Customer[Name], but in both cases you will see a cost in the formula engine that the storage engine cache cannot reduce. However, to enforce the use of a CallbackDataID in this scenario, you can use one of the following two queries, which should never materialize the list of Customer[Name] values to the formula engine:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
SEARCH ( "sim*s", 'Customer'[Name], 1, 0 ) >= 1
)
)
}
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name], "sim*s" )
)
)
}
The DAX expression used in the FILTER condition is included in the argument of the CallbackDataID:

If you use a Power BI Desktop version from before October 2022 or any version of Analysis Services on-premises older than 2022 without subsequent updates, you will see the same execution plan for any text column. If you use a more recent version of Power BI Desktop, Power BI Service, or Azure Analysis Services, then you can see a different behavior when we try the same filter type on a different column such as Customer[Country] in our sample model. For example, consider the following query:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Country], "state" )
)
)
}
This time, the storage engine query filters the United States, the only country containing the word “state”:

However, in an older version of Power BI, you will see this xmSQL query instead:

You can see the same query plan with a CallbackDataID in the downloadable sample file by filtering the Customer[Country non-ASCII] column, which cannot be optimized. This is because it includes non-ASCII characters, as we will see later.
Customer[Country] is thus a column with a more efficient query plan because of the optimization applied to the SEARCH and CONTAINSSTRING functions. However, this optimization is not applied to Customer[Name]. We should understand why we see this difference before addressing the performance issue.
How the optimization works
The first time a query includes SEARCH or CONTAINSSTRING for a column, the engine tries to create an index to improve the performance of such functions. The index created is case insensitive and can be created only when the column contains strictly ASCII characters. The presence of a non-ANSII character in any value of the column stops the generation of the index. This is why we did not see any index applied to Customer[Name]: as we have mentioned before, that column contains values like Šime Šaric, which includes letters with diacritics that are not included in the ASCII set of characters.
Once the index is available, all the executions of SEARCH and CONTAINSSTRING display an almost inexistent execution time. However, the first query executed on a dataset might be slower because of the CPU cost to create the index. The following queries will be faster until the index is valid. Later we will describe the limitations and the conditions when the index is dropped. The index is already applied to Customer[Country], but the columns have such few unique rows that it is impossible to measure the performance differences. To analyze the cost of the index creation and measure its benefits, we implement the optimization on the Customer[Name] column by removing the diacritics.
Optimizing a non-ASCII column
We can simplify the search and take advantage of the index by removing the diacritics from Customer[Name]. Because we do not want to lose the correct name, we create a second column that contains a version of the same names that replaces the diacritics with the corresponding letter, as described in Removing diacritics from text in Power Query in Excel and Power BI (read the limitations of this approach before implementing it in your model).
The Customer[Name ASCII] column is populated by using the following M expression:
= Table.AddColumn (
dbo_Customer,
"Name ASCII", each Text.FromBinary ( Text.ToBinary ( [Name], 28597 ) )
)
We repeat the execution of a query that uses CONTAINSSTRING, but this time on Customer[Name ASCII] instead of on Customer[Name]:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "sim*s" )
)
)
}
The xmSQL query does not have any CallbackDataID, but there is a Search function that includes the search expression because we used a wildcard in the search string:

The presence of the Search function in the xmSQL query is an excellent test to evaluate whether the service supports the index because you would never see the Search function in xmSQL code otherwise.
We can repeat the search by using a word without a wildcard:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "marco" )
)
)
}
This time, the xmSQL query has the list of values that satisfy the condition computed by the formula engine without any additional storage engine query to retrieve the values from Customer[Name ASCII]:

When you see the list of values in the xmSQL query, the SEARCH / CONTAINSSTRING condition has been applied before the execution of the storage engine request. The physical query plan confirms this, and the absence of another storage engine request before the SEARCH node is proof of the use of the index to execute the function.
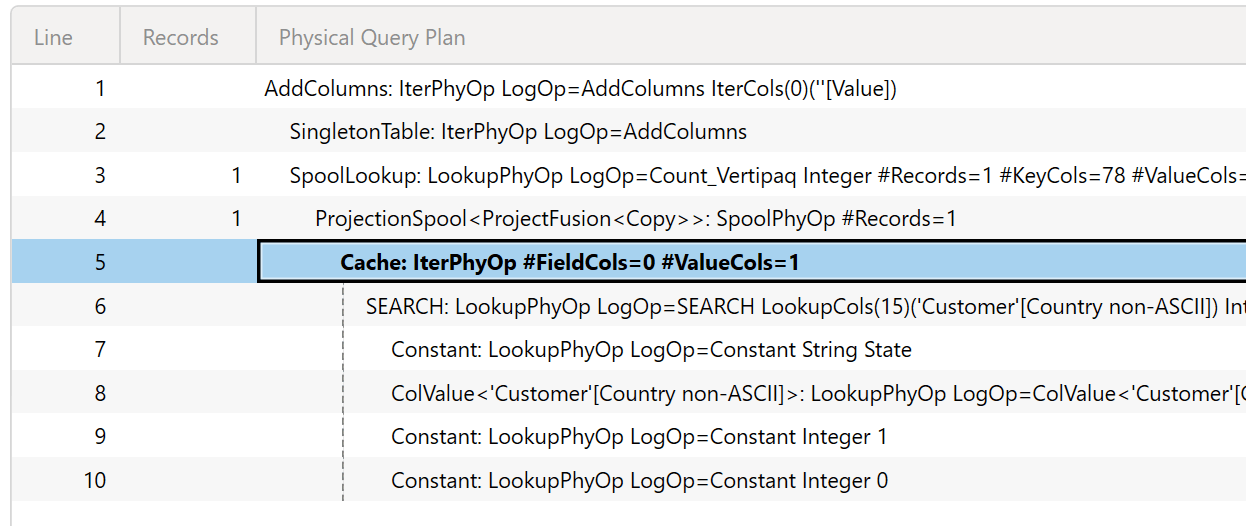
Regardless of the function used (SEARCH or CONTAINSSTRING), the physical query plan should always show a SEARCH node. Indeed, CONTAINSSTRING is just a shortcut to use SEARCH. However, we have seen that Azure Analysis Services might not display that node in the query plan; therefore, it is possible that depending on the engine version, the query plan might not include the SEARCH node, even if it is actually used in the execution.
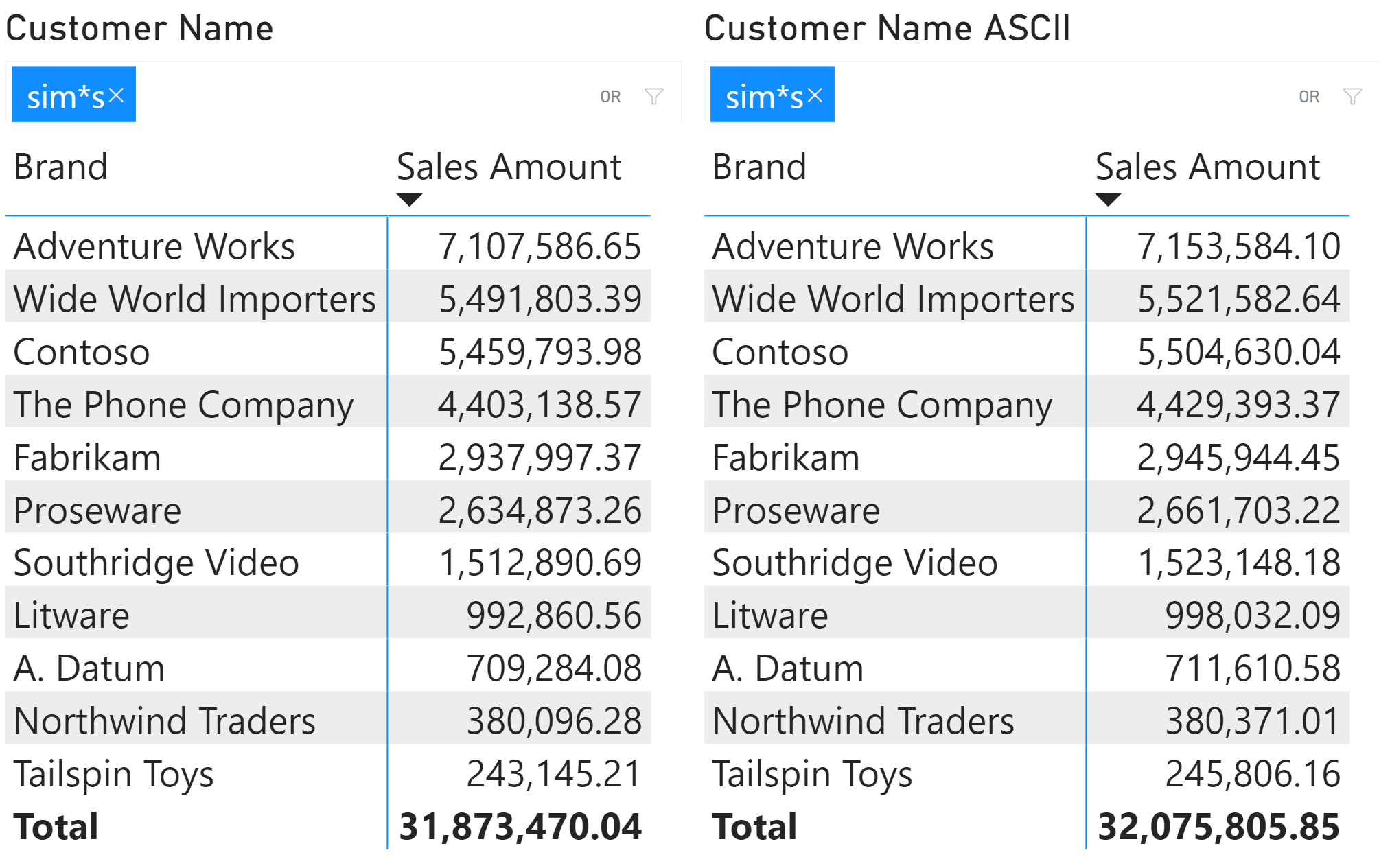
Because the filter applied to ASCII characters can return a different result, the result of a report will also be different. For example, the filter in our examples includes more customers when we use the Customer[Name ASCII] column, so the total amount is also larger than the original filter applied to Customer[Name]. This may be the expected behavior, but pay attention to this side effect once you convert a column to only ASCII characters.
Limitations
The index for SEARCH and CONTAINSSTRING is available in Power BI and Azure Analysis Services. It is not available on SQL Server Analysis Services as of 2022 version – and we do not know whether Microsoft will be including this optimization in future updates of Analysis Services on-premises.
The index is created only for text columns that use strictly ASCII characters. If a single non-ANSI character is present on any value of the column, the index is not created.
The index is case insensitive.
The index is not used by the FIND and CONTAINSSTRINGEXACT functions.
The index is used for the “*” wildcard character but not for the “?” wildcard character.
The index must take less than 25 seconds to buildp. Once the 25 seconds have elapsed, the build times out, and the query is executed without the index being present. The time to build the index is paid by the first query that uses SEARCH or CONTAINSSTRING.
The index is dropped whenever there is an explicit request to clear the cache, or whenever the database is moved out of memory. Here is a more detailed list of conditions that drop the index:
- Analysis Services service or Power BI Desktop is restarted.
- The dataset/database is refreshed.
- The dataset is evicted from memory in Power BI Service.
- Possibly when there is memory pressure on Analysis Services.
There are no limitations related to the security roles. Because the index works at the storage engine level, it can be shared across different users and sessions. Indeed, it is only used to speed up the execution of storage engine queries that always include the security filter conditions.
Measuring performance on large columns
Creating the index can significantly impact columns with a large cardinality: the following test uses the largest version of Contoso we used at the beginning of the article, with 10 million orders and 1.4 million customers.
Before running the first query, we ensure the cache is cleared on run.
The first query we run counts how many customers have the word “marco” in the Name column:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name], "marco" )
)
)
}
The Server Timings pane provides the information we use as a baseline for the following analyses.
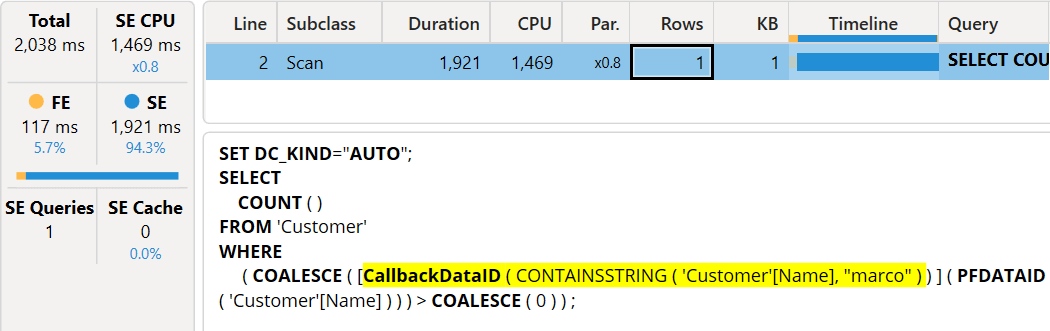
The execution time is around 2 seconds, almost entirely spent in the storage engine because of the CallbackDataID. If we repeat the execution, we always obtain a similar timing regardless of the Clear on Run state: when we disable it, the performance is comparable.
We now run a similar query by filtering Customer[Name ASCII] to test the index performance:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "marco" )
)
)
}
We run the query with Clear on Run active and we look at the server timings pane.
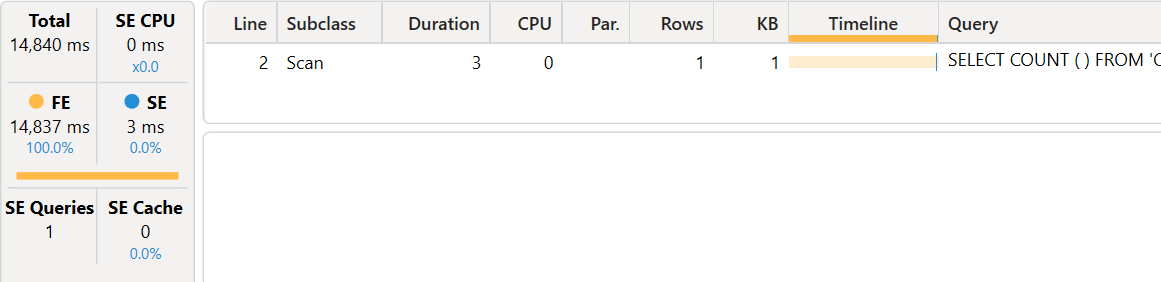
Quite surprisingly, this query is 6-7 times slower than the baseline! However, most of the time spent by the formula engine is time spent creating the index. We did not select the xmSQL query because we want to make sure that the position of the storage engine query is visible: it is at the very end of the execution, and the query plan shows no activity before the storage engine request at line 5.
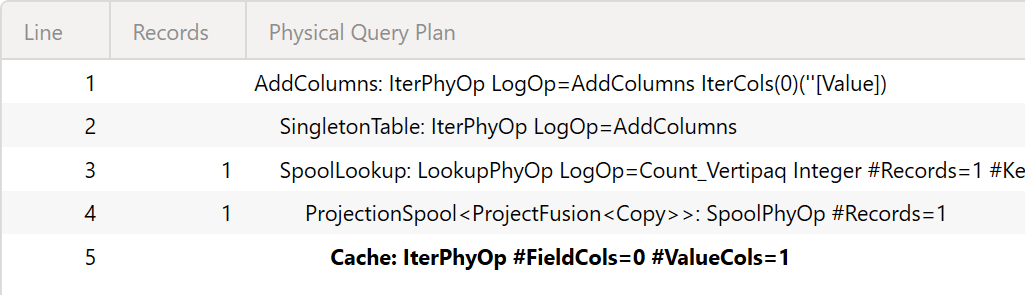
Because the CONTAINSSTRING function does not include any wildcard, there is no SEARCH node in the query plan below the storage engine request. Still, we know that the index is used to materialize the list of values to filter in Customer[Name ASCII].
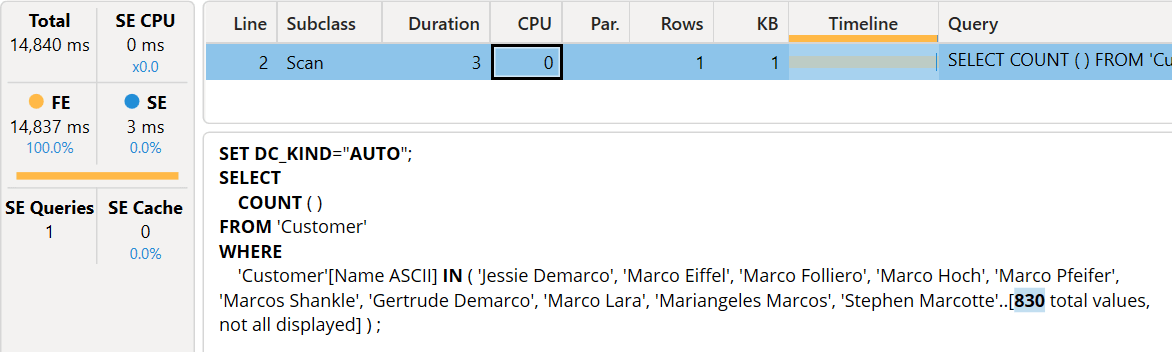
As we have seen, the first execution is 6-7 times slower than our baseline. What happens if we repeat the execution? First, we disable Clear on Run to ensure we no longer clear the index.
At this point, we repeat the execution of the DAX query.
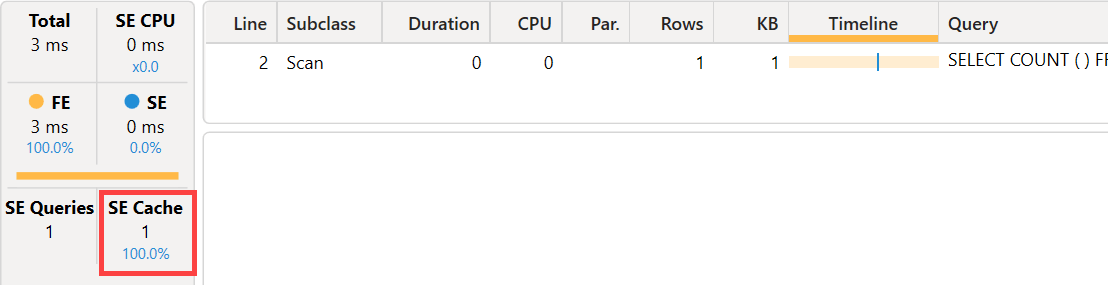
The execution time is now three milliseconds, but the result was already in the storage engine cache. Because there is no CallbackDataID involved, we are simply getting the result of the previous execution of the same xmSQL query. To test whether the index is actually helpful, we change the filter condition using “mark” instead of “marco”:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "mark" )
)
)
}
We run the query while keeping the Clear on Run inactive. We obtain an execution time of just five milliseconds, and this time the xmSQL query is executed by the storage engine and not retrieved from the cache.
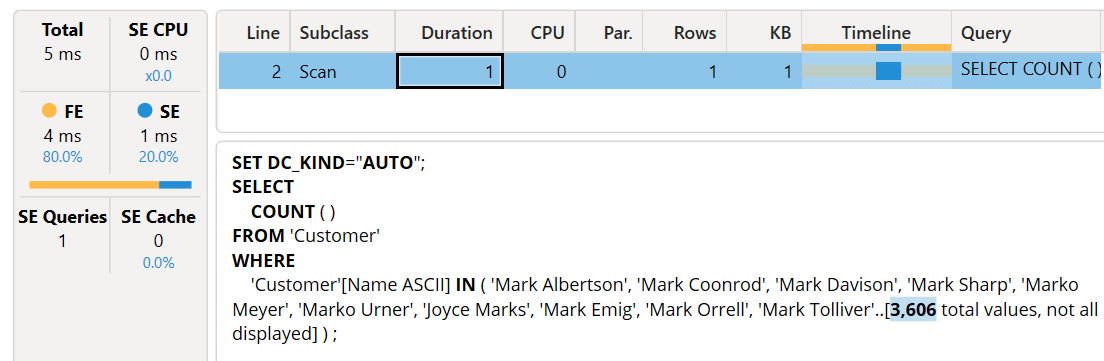
Filtering a complete word provides excellent performance. What happens if we apply a wildcard in the search string? We analyze the performance of the same search pattern we used at the beginning of the article:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "sim*s" )
)
)
}
The result is still faster than our baseline, but not as fast as a search condition without wildcards.
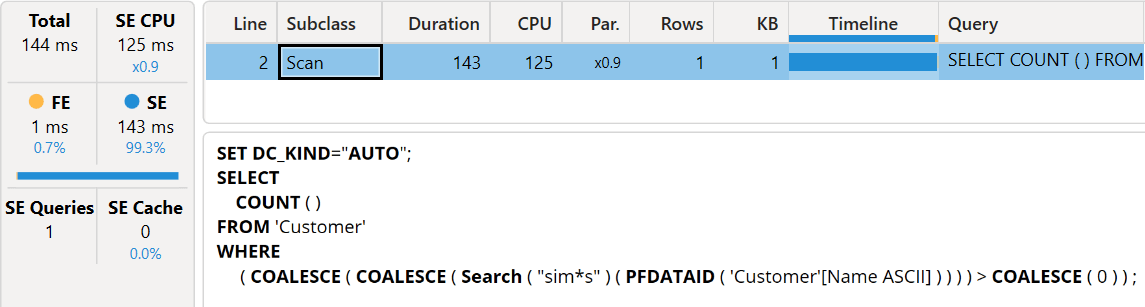
The index improves the performance of SEARCH and CONTAINSSTRING with and without wildcards, although only “*” is supported by the index. If the filter includes the “?” wildcard, the engine reverts the execution plan to CallbackDataID without using the index. However, the first user that queries the model after a refresh must wait up to 15 seconds to see the result, but the index is available to all the following user queries. Usually, it is worth the effort, but you should keep in mind that you rebuild the index every time you test the performance by clearing the cache. If you recognize an index build operation in your benchmark, you must evaluate and remove that time from the typical execution time you measure. In the worst condition for the user, you assume there is an empty storage engine cache, but the index is always available.
Thus, now that we have the index, we can see the execution plan of the original report by applying the filter to Customer[Name ASCII] instead of Customer[Name]. We have already seen that the result differs because of how we filter diacritics. Now it is time to take a look at the Server Timings.
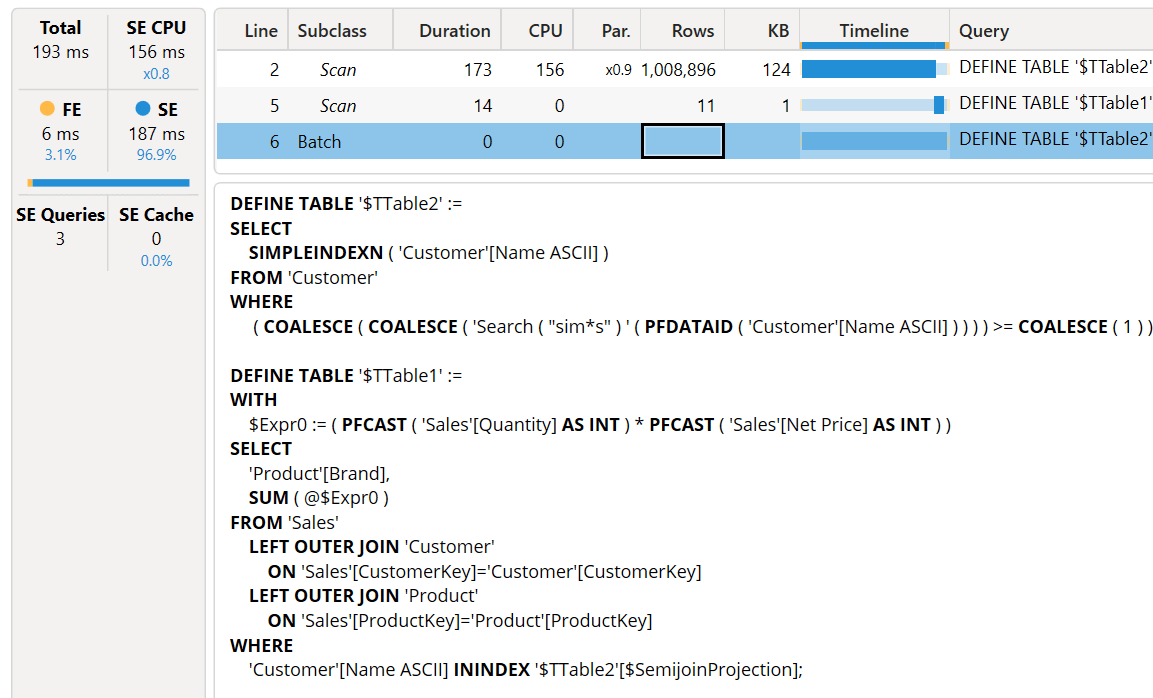
The query plan is similar, but the time needed to create the bitmap index in the first Scan of the batch is reduced to 173 milliseconds from the original 1,927 milliseconds. The index is really effective in optimizing our report.
Conclusions
The SEARCH and CONTAINSSTRING functions can benefit from an index created automatically the first time these functions target a column. To ensure that the index is used, check that the column contains only ASCII characters and that the search argument does not use the “?” wildcard because non-ASCII characters and the “?” wildcard are not supported yet.
The cost of the index build is visible as part of the formula engine activity before the corresponding storage engine request. Understanding this behavior is important to interpret the Server Timings pane information during optimization. Suppose there is a frequent dataset eviction or there are frequent refresh operations; in that case, the index build operation might annoy end users because it may be more expensive than a corresponding CallbackDataID operation. The assumption is that the index is efficient if it is ready to use most of the time.
In certain specific scenarios, you might want to create the index in advance by running specific queries just after the refresh operation. A better solution would be a flag in the Tabular model to request the index build as soon as the dataset is loaded in memory (vote for the idea if interested) instead of waiting for the first query on the column. Another common request is to support the index for non-ASCII characters.
Returns the starting position of one text string within another text string. SEARCH is not case-sensitive, but it is accent-sensitive.
SEARCH ( <FindText>, <WithinText> [, <StartPosition>] [, <NotFoundValue>] )
Returns TRUE if one text string contains another text string. CONTAINSSTRING is not case-sensitive, but it is accent-sensitive.
CONTAINSSTRING ( <WithinText>, <FindText> )
Returns a table that has been filtered.
FILTER ( <Table>, <FilterExpression> )
Returns the starting position of one text string within another text string. FIND is case-sensitive and accent-sensitive.
FIND ( <FindText>, <WithinText> [, <StartPosition>] [, <NotFoundValue>] )
Returns TRUE if one text string contains another text string. CONTAINSSTRINGEXACT is case-sensitive and accent-sensitive.
CONTAINSSTRINGEXACT ( <WithinText>, <FindText> )