 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariVariables are an important element of DAX to improve readability and performance. Variables are created through the VAR keyword, which can be repeated multiple times for multiple variables, followed by RETURN, the keyword that defines the result of the expression.
Evaluating variables
In the following code, we define two variables: SalesAmount and NumCustomers, and finally we divide one by the other to obtain the result:
1 2 3 4 5 6 7 | SalesPerCustomer = VAR SalesAmount = SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ) VAR NumCustomers = DISTINCTCOUNT ( Sales[CustomerKey] ) RETURN DIVIDE ( SalesAmount, NumCustomers ) |
 Copy
Copy Conventions
ConventionsOver time, at SQLBI we got used to a more powerful pattern that requires using Result as the last variable to compute the expression result, so that the last RETURN only returns the Result variable:
1 2 3 4 5 6 7 8 9 | SalesPerCustomer = VAR SalesAmount = SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ) VAR NumCustomers = DISTINCTCOUNT ( Sales[CustomerKey] ) VAR Result = DIVIDE ( SalesAmount, NumCustomers ) RETURN Result |
The rationale behind this choice is simplicity of debugging. Many times, you want to inspect the content of variables because there is a problem with your code. In those scenarios, it is extremely useful to RETURN one of the variables to visualize its content in the context of the report. If your last line is always RETURN Result, when you are done debugging you know exactly how to restore the original code: it is RETURN Result. If, on the other hand, you used a more complex expression for the RETURN part, then you must remember how the measure was before you started debugging.
It is a simple tip, still very powerful when debugging.
One aspect that is not obvious at first sight is that variables can be defined anywhere in your DAX code. Despite mostly using variables at the beginning of the measure, it is totally fine to define a variable in the middle of a complex expression. In this example, you can see that there are two VAR blocks: the outer one starts at the beginning of the formula, the inner one starts inside SUMX:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | Discounted Sales =VAR AverageSales = AVERAGEX( Customer, [Sales Amount] )VAR Result = SUMX ( Customer, VAR CustomerSales = [Sales Amount] VAR Discount = 0.85 VAR Result = IF ( CustomerSales >= AverageSales, CustomerSales * Discount, CustomerSales ) RETURN Result )RETURN Result |
Because there are two VAR blocks, there are two RETURN statements too. Each VAR needs to be closed by its corresponding RETURN. Please note that we used the Result variable twice. The inner Result is valid in the inner block, whereas the outer Result is valid in the outer box.
Result is a somewhat special case. Indeed, the outer Result is not visible in the inner block because it is being hidden by a closer variable with the same name. The AverageSales variable defined in the outer block is still visible and usable in the inner block.
Variables are evaluated in the filter context where they are defined, and their evaluation happens at most once. This is the reason why the CustomerSales variable is so helpful. The value of the sales of the current customer is required three times in the IF statement. Using a variable ensures that the evaluation happens only once, and that the DAX engine does not choose an execution plan requiring multiple evaluations of Sales Amount. The Discount variable, on the other hand, serves no other purpose than to improve the readability of the code. Performance-wise it is useless. However, the code is more readable because of the variable, therefore it makes sense to use the variable in the code.
Variables are evaluated at most once. This is important. Variables are not re-evaluated every time they are used. If a user mistakenly defines the CustomerSales variable before SUMX, the result is inaccurate:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Discounted Sales =VAR AverageSales = AVERAGEX( Customer, [Sales Amount] )VAR CustomerSales = [Sales Amount]VAR Discount = 0.85VAR Result = SUMX ( Customer, IF ( CustomerSales >= AverageSales, CustomerSales * Discount, CustomerSales ) )RETURN Result |
CustomerSales is no longer evaluated for every customer. The value of CustomerSales is determined at the beginning, outside of the iteration over Customer. Therefore, its value is the total sales amount and not, as required by the formula, the sales of the currently-iterated customer.
The following code, on the other hand, works fine. However, it only works because AVERAGEX defines its own iteration to assign AverageSales within the Customer iteration, therefore computing a correct average. Despite being perfectly fine from a DAX standpoint, a human would easily be misguided by the code and spot an error, even though there is none:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | Discounted Sales =SUMX ( Customer, VAR AverageSales = AVERAGEX ( Customer, [Sales Amount] ) VAR CustomerSales = [Sales Amount] VAR Discount = 0.85 VAR Result = IF ( CustomerSales >= AverageSales, CustomerSales * Discount, CustomerSales ) RETURN Result |
Besides, by defining AverageSales inside the iteration, there is the risk (luckily avoided by the DAX engine in this simple scenario) that the average sales amount is computed once per customer.
Choosing the right place to define a variable is important. Readability and correctness of the code are the two goals we must achieve when choosing how many VAR blocks to define.
Variables are constant
A very common error for newbies is to consider a variable as an alias for the code used to define the variable itself. In other words, they consider a variable like a sort of local measure definition. This is not the case: a variable is a name assigned to a value. The value is computed and assigned to the variable once and for all. In other words, variables are – surprisingly enough – constants. Why they are called variables rather than constants is a fact that belongs to the many DAX myths. It is unknown, something lost in the ancient history of the first DAX developers.
Consider the following code, computing the growth against the previous year:
1 2 3 4 5 6 7 8 9 10 | Sales Growth (Wrong) =VAR SalesCY = [Sales Amount]VAR SalesPY = CALCULATE ( SalesCY, SAMEPERIODLASTYEAR ( 'Date'[Date] ) )VAR Result = SalesCY - SalesPYRETURN Result |
In the code, the SalesCY variable is assigned the value of the Sales Amount measure. Later, in the definition of SalesPY, CALCULATE computes the value of SalesCY under a different filter context that shifts the date range one year back through SAMEPERIODLASTYEAR. Despite the filter context being changed, the value of SalesCY does not change. It has been computed during the definition of SalesCY and it is not going to change its value: it is a constant. Therefore, the measure always returns 0. The correct formulation is the following:
1 2 3 4 5 6 7 8 9 10 | Sales Growth =VAR SalesCY = [Sales Amount]VAR SalesPY = CALCULATE ( [Sales Amount], SAMEPERIODLASTYEAR ( 'Date'[Date] ) )VAR Result = SalesCY - SalesPYRETURN Result |
Using the measure rather than the variable completely changes the semantics. A measure is evaluated in the filter context where it is used. Its value changes every time it is invoked, depending on the active filter context.
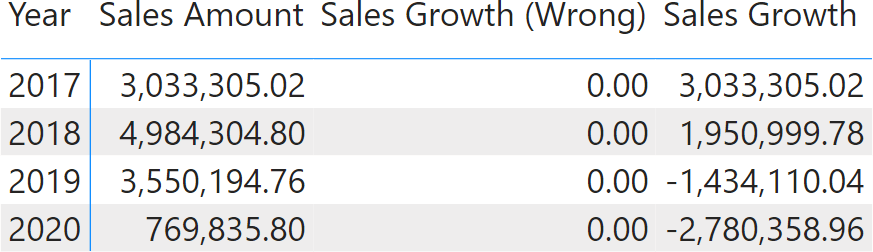
When using variables, always remember that they are constant. A variable just never changes, despite its name suggesting otherwise.
Removing unused variables
An interesting question is: what happens if a variable is defined, but it is not used? Will the engine evaluate the variable or not? From the semantics point of view, there are no differences. If a variable is evaluated and then it is not used, the formula works just fine. However, from a performance point of view, creating variables that are not used may negatively affect the performance of your code.
The rule is quite simple: a variable that is referenced in the code is always evaluated, unless the DAX engine removes the variable references through a static analysis of the code. In simpler words: if the DAX engine has a clear vision of the fact that the variable is useless before even starting the execution of the code, then the variable is physically removed from the code and never evaluated. If the choice between using the variable or not needs to be made at execution time, then the variable will be evaluated, and then may not be used.
To obtain precise performance measurements, we would need to analyze the query plan to check whether a variable is evaluated or not. However, there is an easier technique. If a variable produces an error, then the entire formula returns an error as soon as the variable is evaluated. If the variable is not evaluated, then no error will be present.
Look at the following code:
1 2 3 4 5 6 | Test 1 = VAR Err = ERROR ( "I am your favourite and personal error" ) VAR NumCustomers = DISTINCTCOUNT ( Sales[CustomerKey] ) VAR Result = IF ( NumCustomers < 0, Err ) RETURN Result |
The Err variable just throws an error. NumCustomers contains the number of customers and then Result returns Err only if the number of customers is less than zero. Because it is impossible that the number of customers is a negative number, the formula always returns BLANK. However, the variable is defined and referenced in the code. Therefore, even though we never return the Err variable, DAX needs to evaluate its value. Hence, adding this measure to any report produces an error.
If the variable is defined but not referenced, then it is not evaluated. Therefore, the following code works and always returns BLANK:
1 2 3 4 5 6 | Test 2 = VAR Err = ERROR ( "I am your favourite and personal error" ) VAR NumCustomers = DISTINCTCOUNT ( Sales[CustomerKey] ) VAR Result = IF ( NumCustomers < 0, BLANK () ) RETURN Result |
There is – as we said earlier – a special case where the DAX engine removes references to variables if it knows, just by looking at the code, that the variable will never be used. If we replace DISTINCTCOUNT with COUNTROWS ( ALL () ), then the formula does not return an error anymore, at least in Import mode (the same scenario is different when using different storage engines):
1 2 3 4 5 6 | Test 3 = VAR Err = ERROR ( "I am your favourite and personal error" ) VAR NumCustomers = COUNTROWS ( ALL ( Sales[CustomerKey] ) ) VAR Result = IF ( NumCustomers < 0, Err ) RETURN Result |
The reason for this is that – as part of its optimizations – when in Import mode DAX knows the number of values of each table and column. Therefore, it knows how many values are in the Sales[CustomerKey] column. This number is useful because it means that the COUNTROWS ( ALL ( Sales[CustomerKey] ) ) expression can be replaced by the known value (which is 5585 in our database), thus avoiding the execution of expensive DAX code. In other words, the DAX engine internally rewrites the code this way:
1 2 3 4 5 6 | Test 3 = VAR Err = ERROR ( "I am your favourite and personal error" ) VAR NumCustomers = 5585 VAR Result = IF ( NumCustomers < 0, Err ) RETURN Result |
Then it simplifies it further:
1 2 3 4 5 | Test 3 = VAR Err = ERROR ( "I am your favourite and personal error" ) VAR Result = IF ( 5585 < 0, Err ) RETURN Result |
And finally, because the condition inside IF is known before running the code, it makes it even simpler:
1 2 3 4 5 | Test 3 = VAR Err = ERROR ( "I am your favourite and personal error" ) VAR Result = IF ( FALSE (), Err ) RETURN Result |
Because IF ( FALSE ) will never execute Err, the measure can be further simplified:
1 | Test 3 = BLANK () |
As you see, all variables disappeared from the code. However, this can happen only if the DAX engine checks this before running the code. If the code cannot be statically evaluated (like in DirectQuery mode), then the error appears again.
Using VALUES rather than ALL makes the code dependent on the filter context. Therefore, the values are unknown until the code runs and the engine needs to evaluate all the variables:
1 2 3 4 5 6 | Test 4 = VAR Err = ERROR ( "I am your favourite and personal error" ) VAR NumCustomers = COUNTROWS ( VALUES ( Sales[CustomerKey] ) ) VAR Result = IF ( NumCustomers < 0, Err ) RETURN Result |
Conclusions
As you have seen, variables are evaluated at most once. The only scenario where a variable is not being evaluated is when it is not referenced at all. This can happen because a developer forgot to delete a useless variable, or because the DAX engine identified that a variable will never be used.
Scenarios where the DAX engine can figure out that a variable is not useful are quite rare and it would be wrong to make assumptions about this – which could also change depending on model details like DirectQuery or the presence of attribute hierarchies. As a rule, think about a variable as always being evaluated, regardless of its use in the calculation.
Be mindful that it would be wrong to assume that – because variables are always evaluated – they negatively affect performance. There are indeed some borderline scenarios where removing a variable actually improves performance. However, these cases are so rare, compared to the number of scenarios where variables produce a performance improvement, that the rule is always the same: when you are in doubt about defining a variable or not… define it!
Returns the sum of an expression evaluated for each row in a table.
SUMX ( <Table>, <Expression> )
Checks whether a condition is met, and returns one value if TRUE, and another value if FALSE.
IF ( <LogicalTest>, <ResultIfTrue> [, <ResultIfFalse>] )
Calculates the average (arithmetic mean) of a set of expressions evaluated over a table.
AVERAGEX ( <Table>, <Expression> )
Evaluates an expression in a context modified by filters.
CALCULATE ( <Expression> [, <Filter> [, <Filter> [, … ] ] ] )
Returns a set of dates in the current selection from the previous year.
SAMEPERIODLASTYEAR ( <Dates> )
Returns a blank.
BLANK ( )
Counts the number of distinct values in a column.
DISTINCTCOUNT ( <ColumnName> )
Counts the number of rows in a table.
COUNTROWS ( [<Table>] )
Returns all the rows in a table, or all the values in a column, ignoring any filters that might have been applied.
ALL ( [<TableNameOrColumnName>] [, <ColumnName> [, <ColumnName> [, … ] ] ] )
When a column name is given, returns a single-column table of unique values. When a table name is given, returns a table with the same columns and all the rows of the table (including duplicates) with the additional blank row caused by an invalid relationship if present.
VALUES ( <TableNameOrColumnName> )