In a previous post I spoke about the advantages of having sorted flows in SSIS to greatly speed up data insertion using fastload. The need to have a sorted flow brings some severe problems to the SSIS programmer that he need to be aware of and that IMHO Microsoft should address with a future implementation of SQL Server.
Let’s have a look at the problem.
In the image you can see a very typical SSIS data flow where you need to manage the error flow of a lookup component and go on with the processing. Even if you can’t see it from the picture, think that Sample Source will produce a sorted output of several millions rows and we want to insert into TestTable with the same sorting.
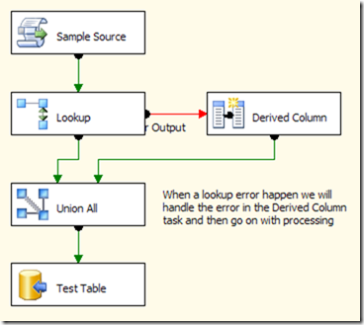
This task works fine but it has a big problem: the Union All component will lose the sorting of the flow as it will handle data from both its input in an unordered way. This is not a bug, Union All has its behaviour by design. Still we have a problem and we know that sorting several millions rows after the Union All component is not an option for memory consumption.
In SSIS you have another component, Merge, that will kindly maintain the order of its inputs, so you can change your package this way:
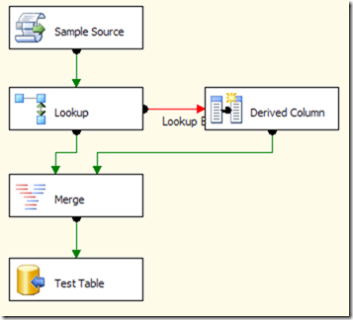
Everything will work fine until you have a package that should handle several millions rows where only a very few of them (say 1.000) will enter the lookup error output flow.
In such a situation Merge will start caching ALL the rows from its first input (the row that correctly matched lookup) until something will come from its second input (rows coming from the Derived Column task). The problem is that SSIS will NOT call the ProcessInput method of the Derived Column task until its buffer reaches a certain amount of rows (normally 10.000 or a number like it) and this will not happen because only 1.000 rows will enter the Derived Column path. In such a situation Merge will start consuming memory and will fill up all the available memory really fast leading to crashes and/or very poor performances.
Even this behavior of both Merge and SSIS is “by design”, so we cannot complain it. But it could be easily solved setting the max number of rows of the buffer in the Derived column to 1 in order to call ProcessInput immediately (if I know what kind of data I will read I can easily set up values that make my SSIS package run faster). Unfortunately there is no such kind of option in SSIS so, at present, the problem cannot be solved.
Needless to say, even if this is a problem, you can try to make your sorted package run without any merge component and you will be able to maintain the sort of the flow but this is a really big limitation in expressivity of your ETL algorithm so awareness of the problem is mandatory to successfully complete your ETL process.
Returns all the rows in a table, or all the values in a column, ignoring any filters that might have been applied.
ALL ( [<TableNameOrColumnName>] [, <ColumnName> [, <ColumnName> [, … ] ] ] )