I recently implemented Power BI models by extracting data from Azure Data Lake Storage (ADSL) Gen 2, and I wanted to share a lesson learned when using this connector.
In this project, I had tens of thousands of CSV files stored in the data lake and organized in different folders according to the Folder Path.
The user interface of Power Query provides the user with two options:
- File System View
- CDM Folder View
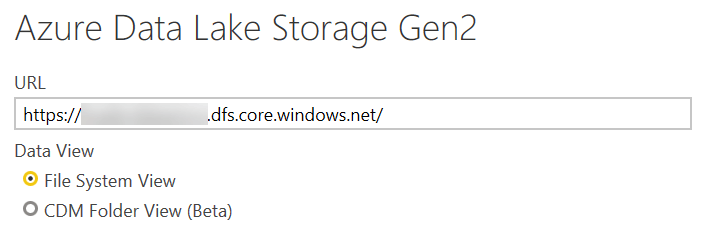
The CDM Folder View is not useful for plain CSV files. By providing the URL of the storage and choosing the File System View, you get access to all the files stored in the data lake regardless of their hierarchical structure. The interesting thing is that when you provide a path, you get the list of all the files included in any subfolder. The list is a plain list, and the hierarchical folder is simply an attribute in this result (Folder Path).
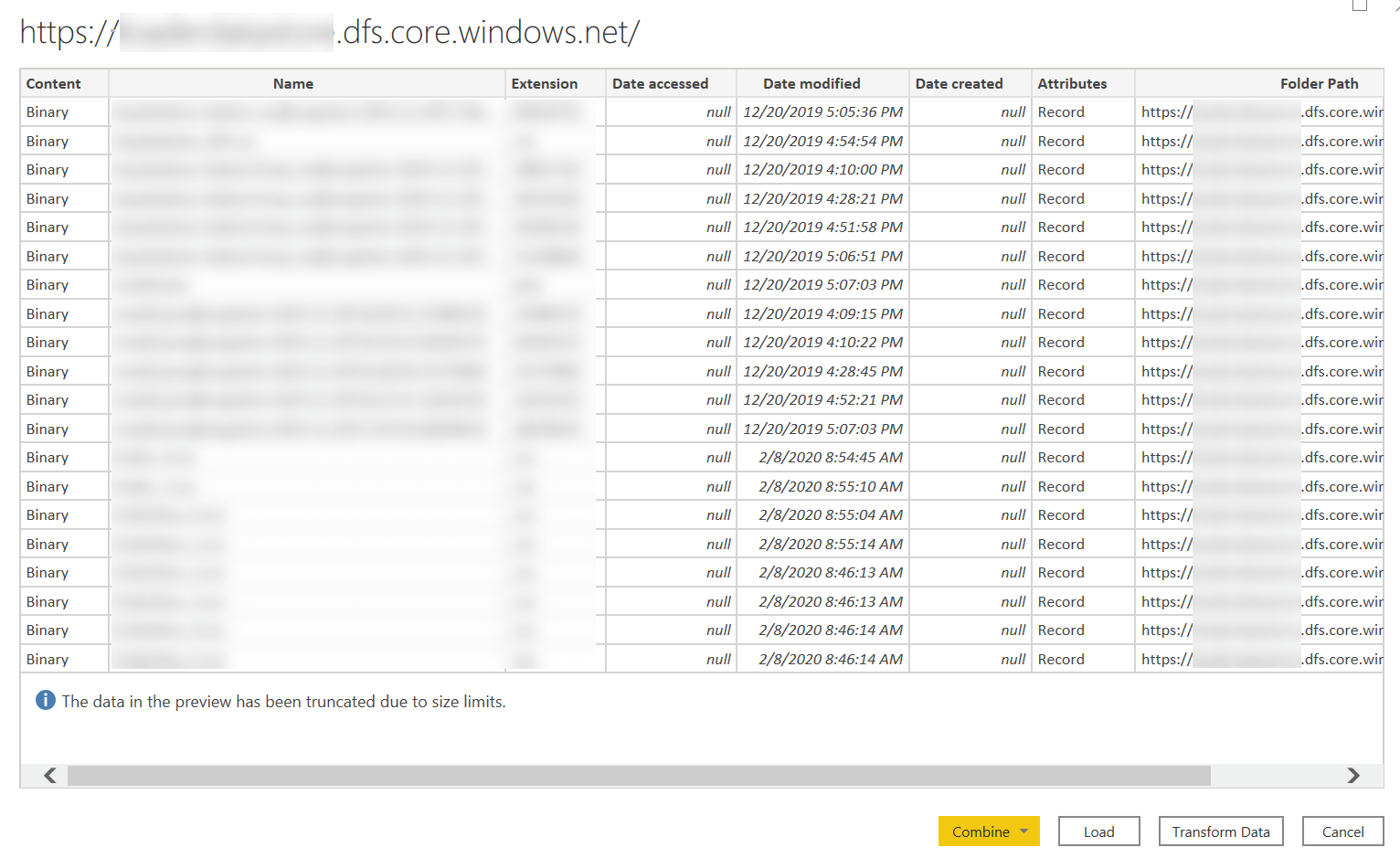
With Power Query you can apply filters to the list obtained by the File System View option, thus restricting the access to only those files (or a single file) you are interested in. However, there is no query folding of this filter. What happens is that every time you refresh the data source, the list of all these files is read by Power Query; the filters in M Query to the folder path and the file name are then applied to this list only client-side. This is very expensive because the entire list is also downloaded when the expression is initially evaluated just to get the structure of the result of the transformation.
A better way to manage the process is to specify in the URL the complete folder path to traverse the hierarchy, and get only the files that are interesting for the transformation – or the exact path of the file is you are able to do that. For example, the data lake I used had one file for each day, stored in a folder structure organized by yyyy\mm, so every folder holds up to 31 files (one month).
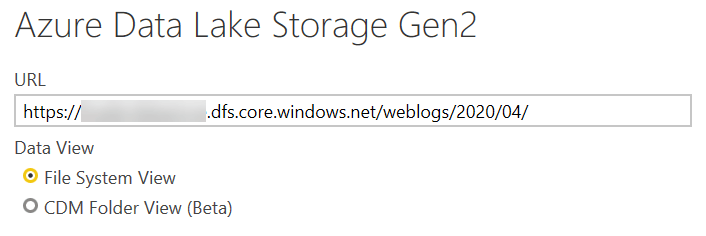
By specifying the folder for April 2020 (2020/04), I get only the 30 files in the list – instead of the tens of thousands obtained when specifying the root folder for the data lake.
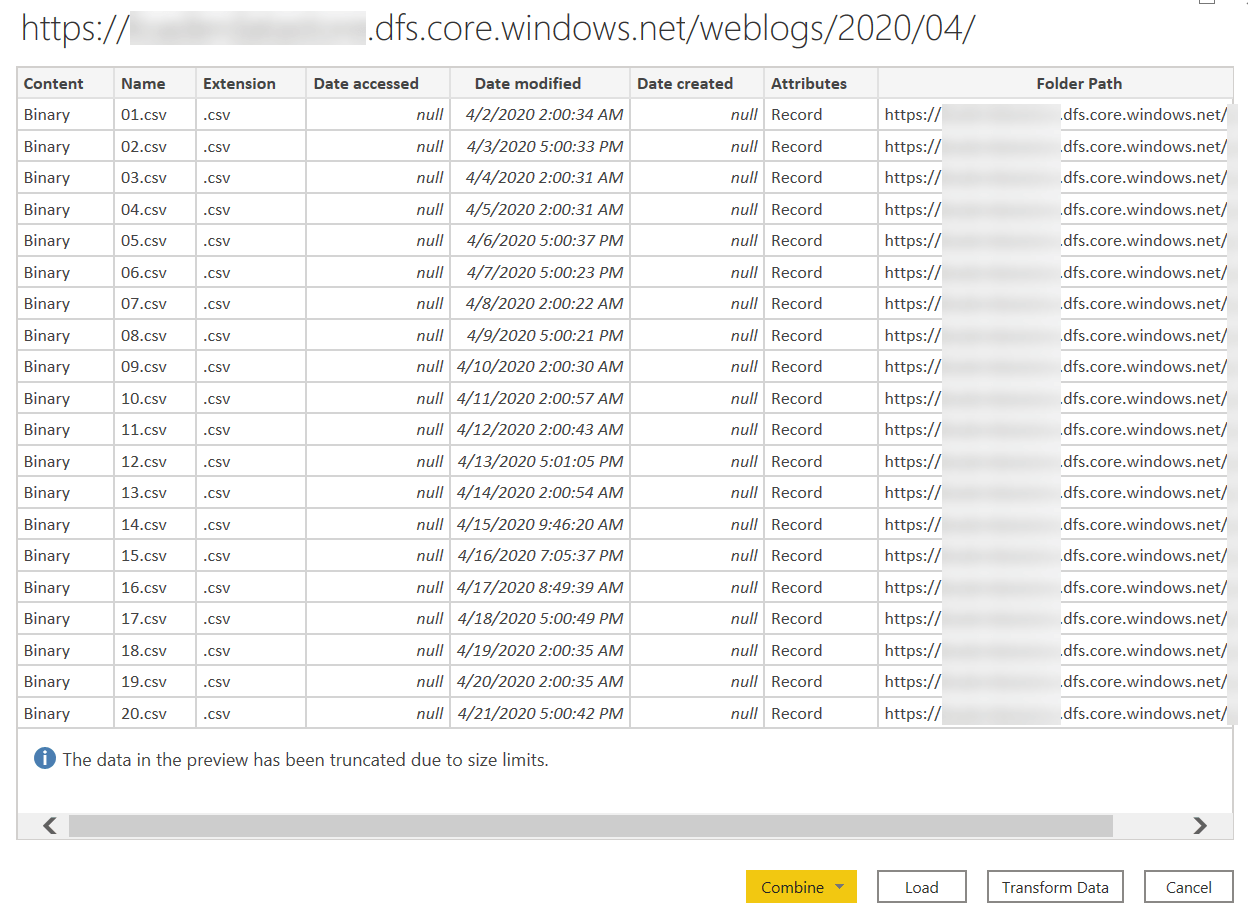
In my project, I modified the transformation of a single CSV file into an M function, so the Sample File transformation was extracting a single file from the data lake; it did so by applying a filter to the list of thousands of file names read from the data lake.
This was the initial code to extract the 15.csv file from a certain folder of the data lake:
let
Source = AzureStorage.DataLake("https://<storagename>.dfs.core.windows.net/ "),
#"Filtered Rows" = Table.SelectRows(
Source,
each (
[Folder Path]
= "https://<storagename>.dfs.core.windows.net/weblogs/2020/04/")
and ([Name] = "15.csv")),
Navigation1 = #"Filtered Rows"{0}[Content]
in
Navigation1
This is an improved version of the code, where the filter over the folder has been moved to the initial URL:
let
Source = AzureStorage.DataLake(
"https://<storagename>.dfs.core.windows.net/weblogs/2020/04/"),
#"Filtered Rows" = Table.SelectRows(Source, each ([Name] = "15.csv")),
Navigation1 = #"Filtered Rows"{0}[Content]
in
Navigation1
This way, we are still reading all the files of April 2020 in the data lake, corresponding to the final 2020/04 branch of the URL. This step alone solved the performance issue – but if you need a single file and you know its name, there is a better way to do that. In the connection string, specify the complete path including the filename.
This way, the list only has one file.
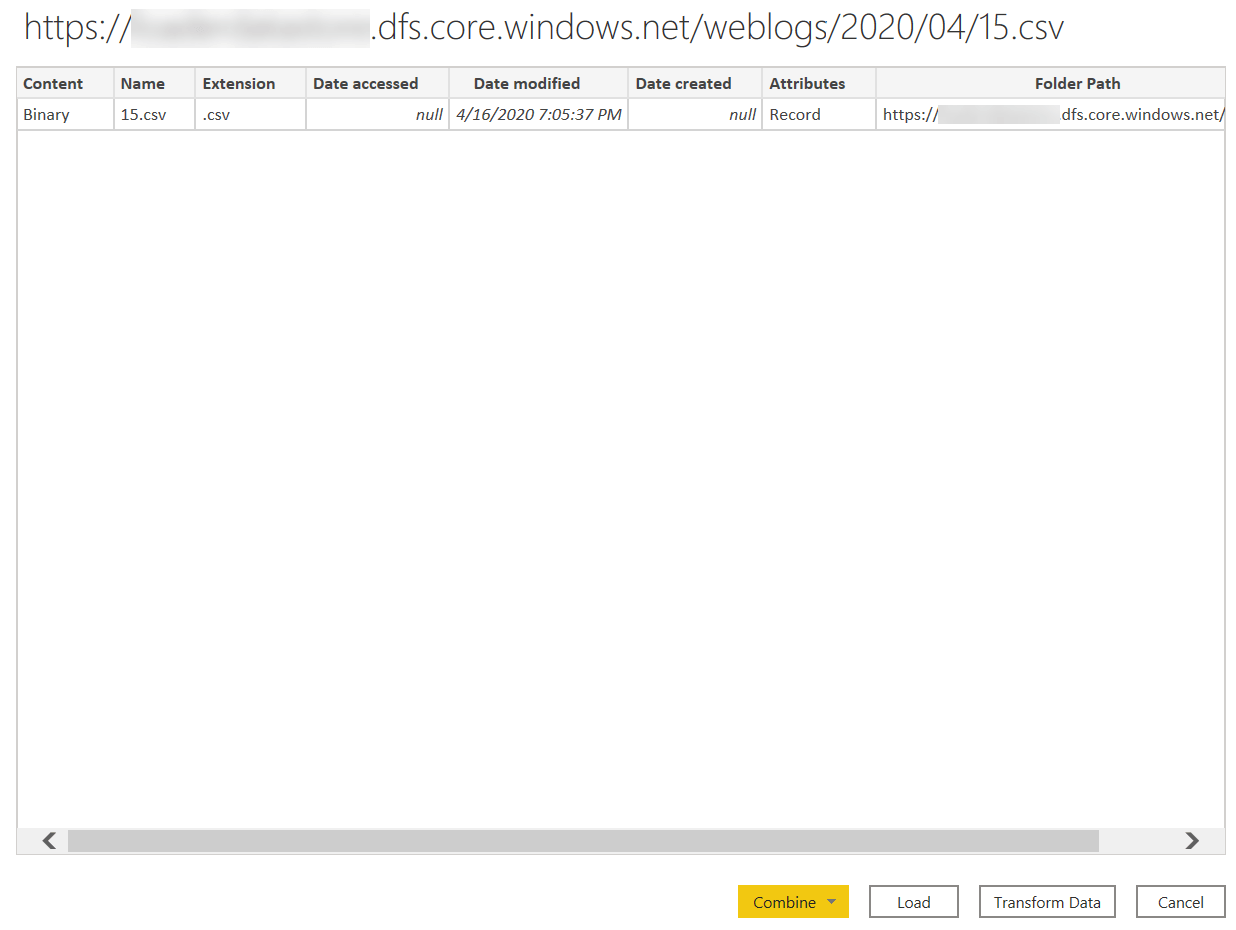
In my code, I changed the complete path including the filename in the argument of AzureStorage.DataLake:
let
Source = AzureStorage.DataLake(
"https://<storagename>.dfs.core.windows.net/weblogs/2020/05/01.csv" ),
CsvContent = Source[Content] {0}
in
CsvContent
The performance difference is huge, especially when you use this transformation to create an M function in Power Query. The same code must be executed for every file, so reading three years of data requires calling the same function over 1,000 times. Reading a list of one file 1,000 times is much better than reading a list of thousands of files 1,000 times!
The lesson is that when using the AzureStorage.DataLake connector in Power Query you should always provide a path that restricts the files returned, or just one file if you know the filename.